
왜 쓰게 되었는가?
서비스를 분석하기 위해 유저의 활동 데이터를 수집해야 한다. frontend layer에서 firebase, mixpanel, airbridge 등의 다양한 툴을 붙여서 분석하고 있지만 전체적인 유저의 추세를 보기에는 간편하고, 시각화도 잘 해주지만 유저 한명한명을 타게팅해서 뭐하나 분석하기엔 어려움이 있었다.
backend layer에서는 API를 호출할 때마다 로그를 기록하면되니, 로그만 잘 작성해둔다면 유저가 어디에서 머물고, 어떤 버튼을 클릭하고, 어디에서 이탈하는지 분석할 수 있을것이다.

원래는 어떻게 했는가?
원래도 logging 기능은 있었다.
import logger from "../../utils/winston";
...
isUserPriorty: async (_, { USER_FK }, context) => {
try {
const result = await priority.checkUserPriority(USER_FK);
logger.info(
`isUserPriorty API로 ${USER_FK} 우선순위 유무 조회`
);
return result;
} catch (error) {
Sentry.captureException(`Catched Error : ${error}`);
return false;
}
},nodejs에서 주로 쓰는 라이브러리인 winston을 사용해서 아래와 같은 예시로 log를 기록했다. 대부분의 로그는 이런식으로 기록하고 log폴더에 log 레벨별로 구분되어 들어갔다.(거의 디버깅을 위한 구색 수준...)
근데 여기서 문제가 elasticbeanstalk(이하 EB)로 자동으로 CI/CD를 달아 배포하다보니, 직접적으로 EC2서버에 내가 접근할 일은 없었고(굳이 접근하려고 하면 ssh 접속은 할 수 있다) scp 명령어로 경로지정해서 log 폴더만 내려받기 해도 되긴한데, 22포트를 열어놔야 하는 보안상 단점도 있었다. 결정적으로 EB 특성상 배포할 때 아예 EC2를 갈아끼우기 때문에(설정으로 바꿀순 있음) 폴더가 날아가는 단점도 있다.
그래서
외부?에 로그를 저장할 필요가 있었다. 지금쓰고있는 RDB에 때려박아도 될것 같긴한데, 무한랜더링 등의 상황에서 api가 비정상적으로 호출될 때 실DB에 부하를 주면 안될 것 같기도하고, 혹시나 로그 확인해볼 일이 많은데 그때마다 DB를 까보니엔 좋지 못하다고 생각했다.
시각화까지 자동으로 연결되고, 특정 상황 검색에도 용이한 elasticsearch(이하 ES) + kibana 조합을 쓰기로 했다.

처음에 local에 세팅하고 곰곰이 생각해보니 '이걸 쓰려면 EC2에 생으로 띄워야하나?' 생각이 들었다.. 하지만? 우리의 AWS는 이미 다 가지고 있었다. 심지어 프리티어 1년무료?

설명을 보니 원래 ElasticSearch 서비스가 있다가 AWS 자체적으로 opensearch라는 호환되는 성능좋은 비슷한걸 만든게 아닌가 하는 생각이 든다.
Setting AWS
1. 도메인 이름을 설정해준다. (table name이랑 비슷한느낌으로 보면 편할 듯)
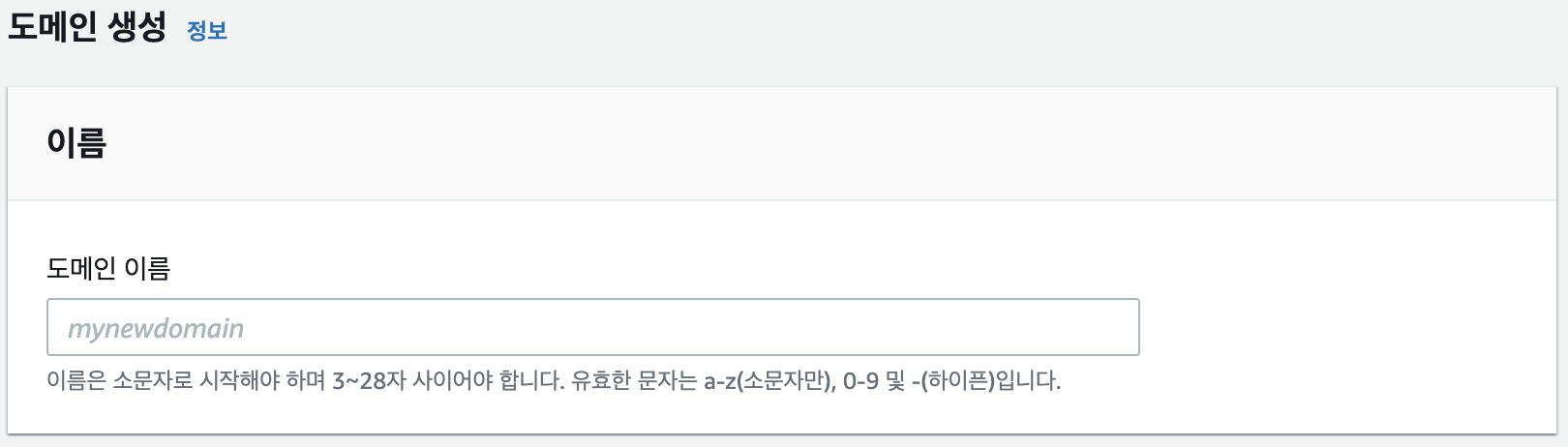
2. 배포 유형을 선택해준다. 본인은 opensearch 대신 elasticsearch 7.10 (AWS에서 지원하는 최신버전)을 사용하였다.
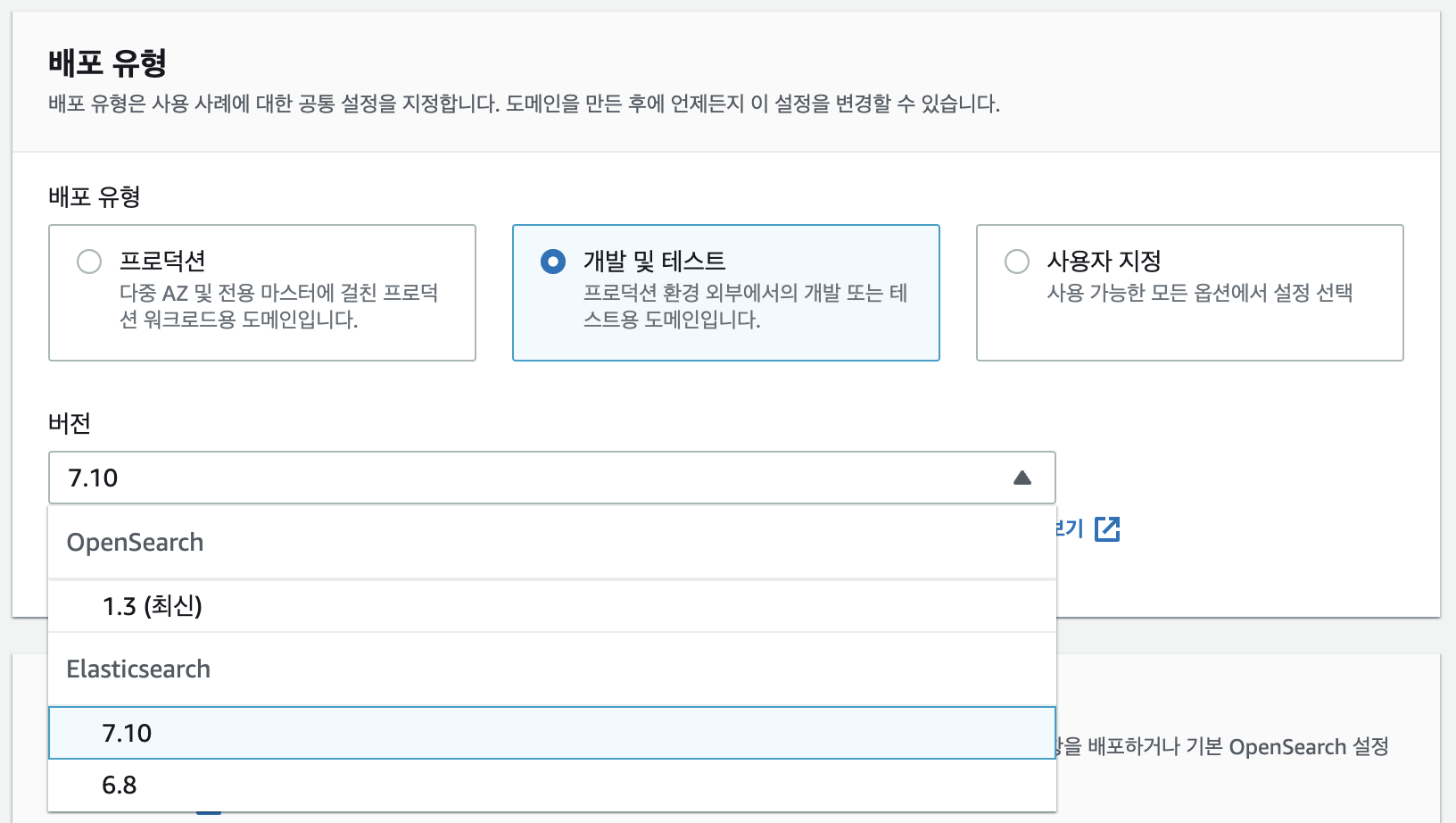
3. 뭔지는 정확히 모르겠으니 일단 비활성화
4. 인스턴스 유형을 프리티어로 설정
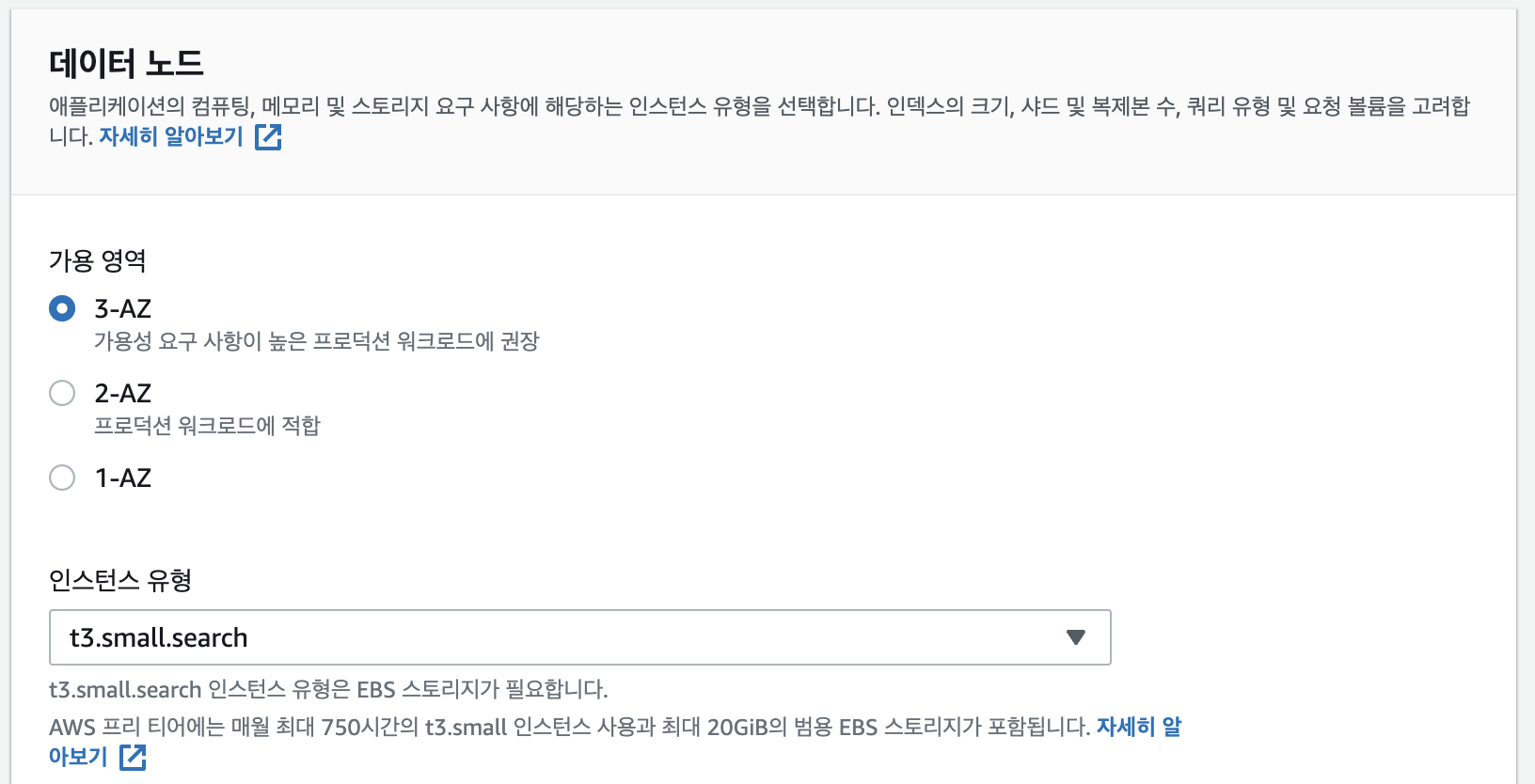
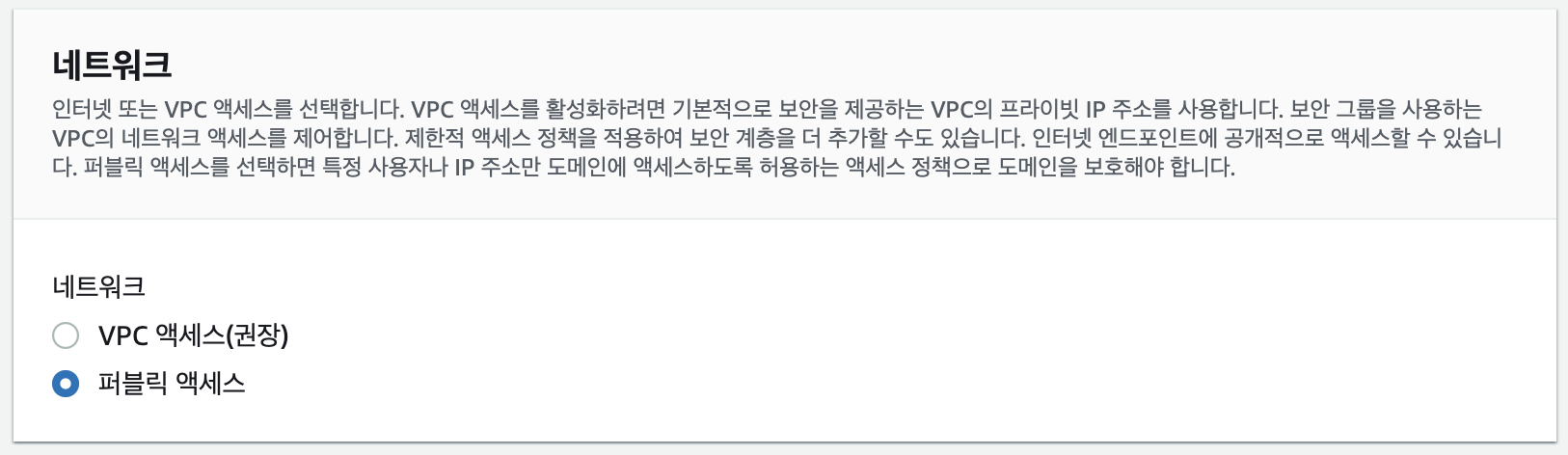
5. 일단은 퍼블릭 엑세스로 테스트를 위해서 사용, 나중에는 VPC안에 deploy 서버와 묶어서 관리해야 안전할듯하다.
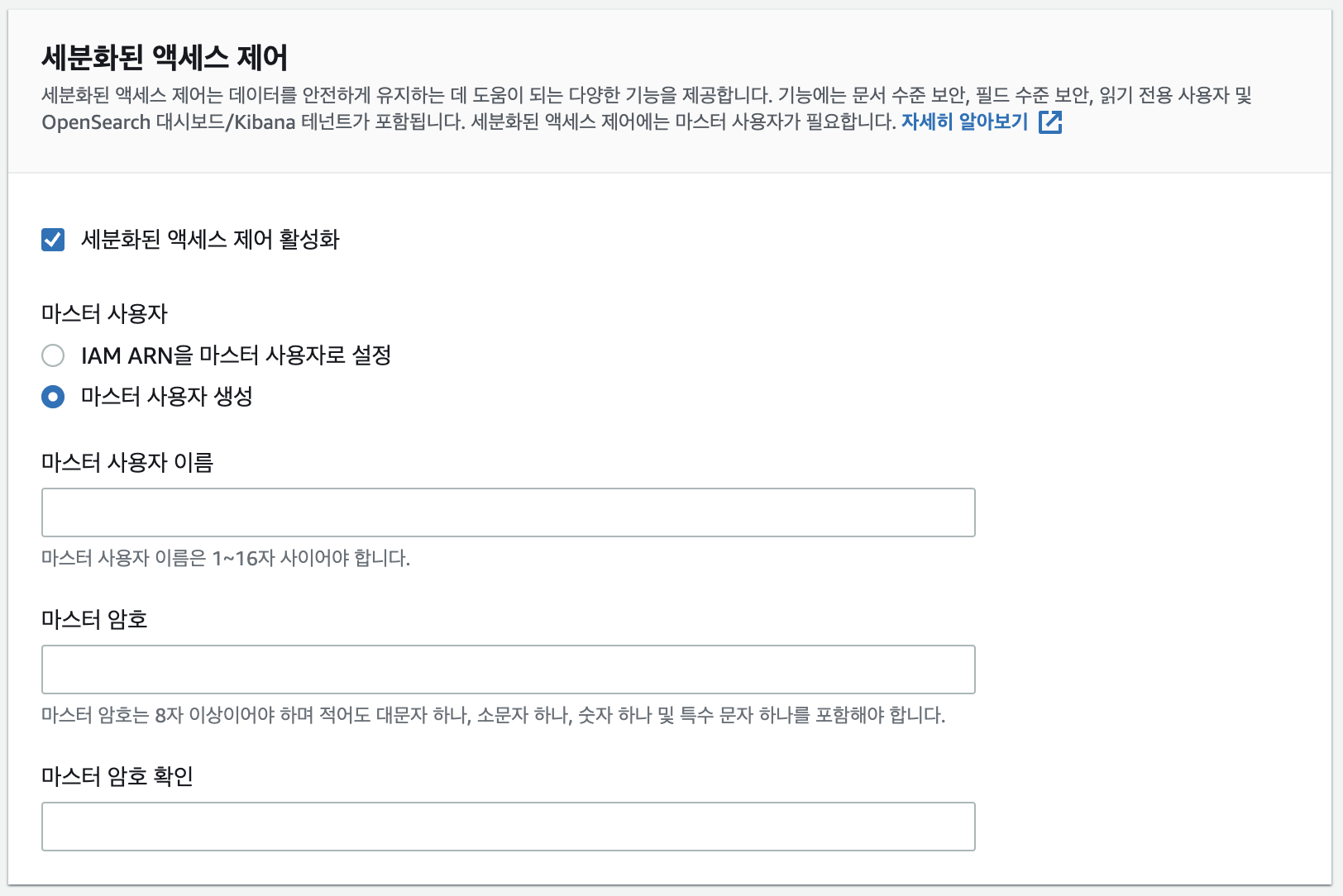
6. 사용할 id, pw를 입력해준다.(ES나 kibana 접근시에 사용된다)
나머지는 default 값 유지해서 생성했다.
정확히 재본건 아니지만 20분 내외로 생성하는데 시간이 꽤나 걸렸다.
insomnia(postman 같은것)로 엔드포인트를 넣고 테스트해보니까 잘되었는데, 이때 꼭 auth에 basic auth로 설정해서 username과 password를 같이 보내줘야했다.
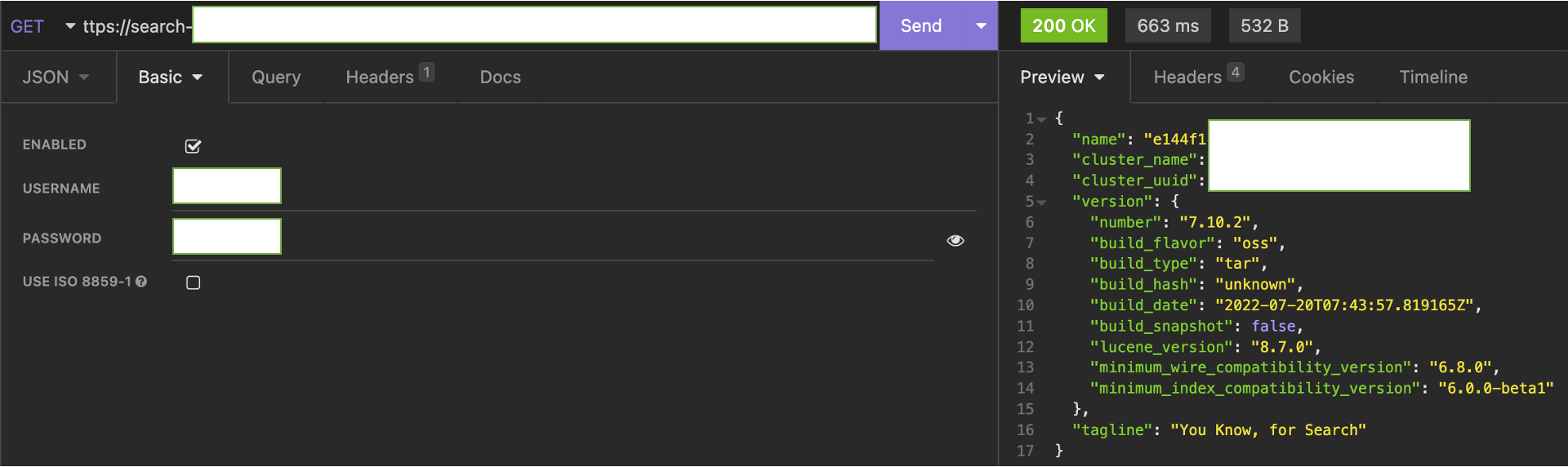
NodeJS에서 로그 보내기
로그 정보에 어떤걸 담아야할지는 좀 더 고민해봐야하겠지만 기본적인 연결 방법이다. npm에 연결 툴이 있었고, 이를 바탕으로 logging을 위한 함수를 만들었다.
import { Client } from "@elastic/elasticsearch";
let ES_ENDPOINT = process.env.ES_ENDPOINT;
const client = new Client({
node: ES_ENDPOINT,
auth: {
username: process.env.ES_USERNAME,
password: process.env.ES_PASSWORD,
},
maxRetries: 5,
requestTimeout: 60000,
});
async function linkElasticsearch() {
client.ping();
}
linkElasticsearch();
const esLogger = async (log_level, user_id, api_name, description, tags) => {
if (process.env.NODE_ENV === "production") {
try {
await client.index({
index: "ddakzip_log",
body: {
timestamp: new Date(),
log_level: log_level,
user_id: user_id,
api_name: api_name,
description: description,
tags: tags,
},
});
} catch (err) {
console.log(err);
}
}
};
module.exports = esLogger;처음에 local환경에서는 잘되다가 테스트 서버에 배포했더니 아래와 같은 에러를 뱉었다. ProductNotSupportedError: The client noticed that the server is not Elasticsearch and we do not support this unknown product.
구글링해보니 해당 npm package와 ES의 version을 일치해줘야 하는 문제였다.
npm install @elastic/elasticsearch@7.10.0 --save-exact버전을 명세해서 새로 install해서 해결했다.
Kibana에서 확인해보니 로그가 잘 기록되었다.
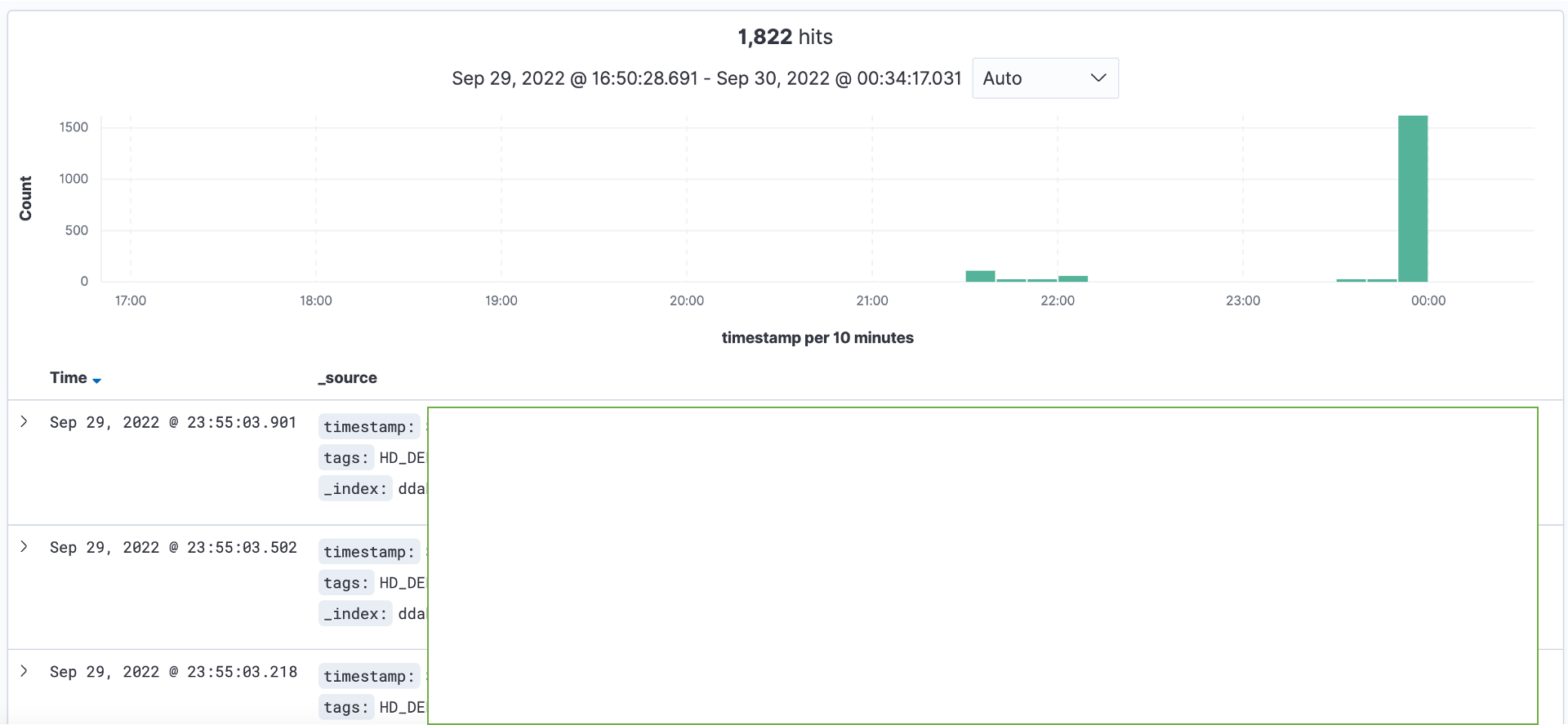
참고 블로그
https://leesungki.github.io/gatsby-aws-history-of-opensearch-tuto/
'인프라 > AWS' 카테고리의 다른 글
| [AWS] AWS S3 + CloudFront + Route53으로 https로 React 웹 호스팅하기 (0) | 2022.11.19 |
|---|---|
| [AWS] Amazon SES에 자체 도메인 연결하고, Node.js 환경에서 메일 발송하기 (0) | 2022.11.10 |
| [AWS] Elastic Beanstalk에서 고용량 파일(이미지)을 받을 때 nginx 설정 (0) | 2022.07.18 |
| [AWS] Github Action을 사용해서 Elastic Beanstalk에 nodejs 서버 CI/CD (0) | 2022.07.18 |
| [AWS] nodejs 에서 multer를 사용해 AWS S3에 이미지(파일)를 업로드하는 API 만들기(feat. AWS IAM 사용자 보안 설정) (0) | 2022.07.14 |